云上应用系统数据存储架构的演进 数据处理与存储支持服务的变革之路

随着云计算技术的深入发展,云上应用系统的数据存储架构经历了从单一到多元、从集中到分布、从静态到智能的深刻演进。这一演进过程不仅反映了技术能力的跃迁,更体现了业务需求对数据处理与存储支持服务提出的新要求。本文将梳理这一演进历程,并探讨其背后的驱动力与未来趋势。
第一阶段:集中式存储与关系型数据库主导期
在云计算的早期阶段,云上应用系统的数据存储架构很大程度上是传统本地化架构的云端迁移。其核心特征是采用集中式的块存储或文件存储服务,并搭配成熟的关系型数据库服务(如云托管的MySQL、PostgreSQL、SQL Server)。数据处理逻辑通常紧密耦合在应用代码中。此时的“存储支持服务”主要提供高可用、备份恢复、基础监控等保障性功能,目标是实现数据的可靠持久化。这种架构简单、一致性强,但面对海量数据、高并发访问及半结构化/非结构化数据时,扩展性、灵活性和成本效益面临挑战。
第二阶段:分布式、多模数据库与对象存储兴起
当Web 2.0、移动互联网爆发式增长,数据量、并发量和数据类型多样性激增,架构演进进入第二阶段。核心变化是分布式理念的普及和专用数据库(数据库) 的兴起。
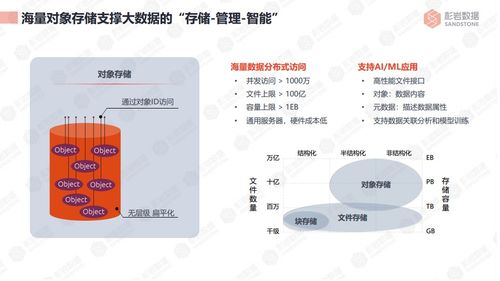
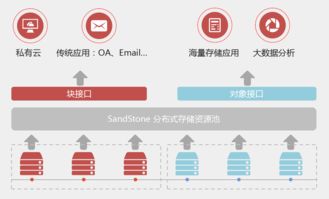
1. 存储分层:对象存储(如AWS S3、阿里云OSS)因其近乎无限的容量、高持久性和低成本,成为海量非结构化数据(图片、视频、日志、备份)的首选。
2. 数据库分化:为解决关系型数据库的扩展瓶颈,出现了各类NoSQL数据库(如键值存储Redis/DynamoDB、文档数据库MongoDB、宽列存储Cassandra/HBase、图数据库Neo4j)以及分布式NewSQL数据库(如Google Spanner、TiDB)。数据处理开始根据访问模式(如低延迟读写、复杂关联查询、海量吞吐)选择最适合的存储引擎。
3. 数据处理服务化:云厂商开始提供托管的分布式数据处理服务,如批处理(Hadoop/Spark on Cloud)、流处理(Kafka、Flink托管服务)。存储与计算进一步分离,数据湖概念萌芽。
此阶段的“支持服务”扩展到弹性伸缩、跨区域复制、细粒度安全策略(如IAM集成)、以及初步的数据索引与查询服务(如对象存储上的查询加速)。
第三阶段:云原生、存算分离与智能数据平台
当前,我们正处在以云原生和智能化为标志的第三阶段。容器化、微服务、Serverless成为应用构建的主流范式,这深刻影响了数据架构。
- 存算彻底分离与数据湖仓一体:计算资源(如无服务器函数、弹性容器实例)与存储资源(对象存储、云原生数据库)独立弹性伸缩,成本与效率达到新平衡。基于对象存储构建的数据湖,与经过优化、支持强Schema和高效分析的云原生数据仓库(如Snowflake、BigQuery、Databricks SQL)走向融合,形成“湖仓一体”架构,兼顾灵活性与性能。
- 全托管与Serverless数据库服务:数据库服务进一步抽象,用户无需关心底层节点、分片和集群管理,只需按实际消耗的资源(如读写次数、存储量)付费。这极大降低了运维复杂度。
- 数据处理与存储支持服务的智能化与一体化:
- 智能分层与生命周期管理:存储服务能基于访问频率自动在热、温、冷、归档层间移动数据,实现成本最优。
- 内置数据处理能力:存储层本身集成更强大的计算能力,例如对象存储支持原生SQL查询、事务能力,或与计算引擎深度集成实现“零ETL”分析。
- 统一的数据治理与安全:提供跨多种数据源和存储服务的统一元数据管理、数据目录、数据血缘、质量监控和隐私合规(如数据脱敏、加密)服务。
- AI增强:利用机器学习优化数据布局、预测性能瓶颈、自动进行索引优化与查询调优。
驱动力与未来展望
这一演进背后的核心驱动力是:业务敏捷性需求(快速上线、迭代)、数据规模与复杂性爆炸(大数据、多模态)、成本效率追求(按需付费、精细化运营)以及安全合规要求(全球化部署、隐私保护)。
云上数据存储架构将继续向以下方向发展:
- 异构计算的深度融合:利用GPU、FPGA等加速特定数据处理负载(如AI推理、实时分析)。
- 边缘-云协同数据架构:为物联网、实时交互应用提供统一的数据视图和管理能力。
- 数据架构的完全声明式与自治管理:用户只需声明数据需求(如一致性等级、延迟、成本上限),系统自动配置并优化底层资源。
- 隐私计算与数据安全:在保证数据可用不可见的前提下,支持跨组织的数据联合分析与价值挖掘。
总而言之,云上应用系统数据存储架构的演进,是从单一工具到生态体系、从资源供给到价值服务的蜕变。数据处理与存储支持服务已不再是静态的后端支撑,而是动态、智能、与业务创新紧密相连的核心竞争力组成部分。企业构建现代应用时,必须将数据架构的演进趋势纳入战略考量,以充分释放数据的潜能。
如若转载,请注明出处:http://www.bswoniu.com/product/60.html
更新时间:2026-03-06 23:50:35