数据清洗的关键方法及数据处理与存储支持服务
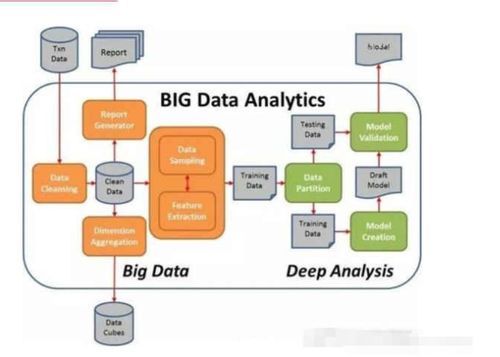
在当今数据驱动的时代,数据质量直接影响到分析结果与决策效能。数据清洗作为数据预处理的核心环节,旨在识别并修正数据集中的错误、不一致与缺失,确保数据的准确性、完整性与一致性。与此高效的数据处理与存储支持服务为数据的高效流动与价值挖掘提供了坚实基础。本文将系统梳理数据清洗的常用方法,并探讨数据处理与存储支持服务的关键组成部分。
一、数据清洗的主要方法
数据清洗是一个多步骤的迭代过程,具体方法可根据数据问题的类型进行选择与应用,主要包括:
- 处理缺失值:数据中常见的空值或占位符需妥善处理。方法包括直接删除含有缺失值的记录(在缺失比例较小时适用)、使用统计量(如均值、中位数、众数)进行填充、使用算法(如回归、K近邻)基于其他特征预测填充,或明确标记为“未知”类别。
- 处理重复数据:识别并移除完全相同的记录或基于关键字段判定的重复记录,以避免分析偏差。
- 纠正格式与不一致性:统一数据格式,例如将日期统一为“YYYY-MM-DD”,将文本大小写标准化,纠正拼写错误,并确保分类数据(如“男”、“男性”统一为“男”)和单位(如“kg”与“千克”)的一致性。
- 处理异常值:识别明显偏离整体分布的数据点。可通过统计方法(如利用标准差或四分位距划定合理范围)、可视化方法(如箱线图)或基于模型的异常检测来识别。处理方式包括分析原因后修正、视为特殊情况保留或直接删除。
- 数据转换与规范化:为满足分析需求,可能需要进行数据转换,例如将连续数据分箱(离散化)、对数值数据进行标准化(如Z-score标准化)或归一化(缩放到[0,1]区间),以消除量纲影响。
- 数据验证与业务规则检查:依据预定义的业务规则或约束条件(如年龄不能为负数,订单金额需大于0)对数据进行校验,确保其符合逻辑与业务常识。
二、数据处理与存储支持服务
数据清洗后,高效、可靠的数据处理与存储是支撑数据应用的关键。相关支持服务通常涵盖:
- 数据处理流水线与服务:提供自动化的数据抽取、转换、加载(ETL)或更灵活的抽取、加载、转换(ELT)服务。这些服务能够调度和执行复杂的清洗转换任务,处理大规模数据流(流处理)或批量数据(批处理),并将处理后的数据输送到指定目的地。
- 数据存储解决方案:根据数据的结构、访问模式和需求,提供多样化的存储支持:
- 关系型数据库:适用于需要强一致性、复杂查询和事务处理的结构化数据(如MySQL, PostgreSQL)。
- NoSQL数据库:适用于半结构化或非结构化数据,包括文档型(如MongoDB,适合JSON文档)、键值型(如Redis,适合高速缓存)、列存储型(如HBase,适合海量数据分析)和图数据库(如Neo4j,适合关系网络分析)。
- 数据仓库:如Amazon Redshift、Snowflake、Google BigQuery等,专为大规模数据分析、聚合和商业智能报表优化,支持复杂的OLAP查询。
- 数据湖:如基于HDFS或云对象存储(如AWS S3)构建,能够以原生格式存储海量原始数据(包括结构化、半结构化、非结构化),为探索性分析和机器学习提供灵活性。
- 数据管理与治理服务:提供数据目录、元数据管理、数据血缘追踪、数据质量监控和主数据管理(MDM)等服务,确保数据在整个生命周期中的可发现、可理解、可信与安全合规。
- 云平台与托管服务:主流云服务商(如AWS, Azure, GCP)提供全托管的数据处理与存储服务,极大地降低了基础设施管理的复杂度,用户可按需使用计算、存储及各类数据库服务。
- 性能优化与运维支持:包括存储架构设计咨询、查询性能调优、容量规划、高可用与容灾备份方案的部署与维护,确保数据系统的稳定、高效运行。
数据清洗通过一系列系统方法为数据质量保驾护航,而专业的数据处理与存储支持服务则为清洗后的数据提供了组织、保存、管理和价值变现的舞台。二者紧密结合,共同构成了现代数据价值链中不可或缺的基石,赋能企业从数据中获取精准洞察与决策依据。
如若转载,请注明出处:http://www.bswoniu.com/product/39.html
更新时间:2026-02-24 09:28:48